Forecasting GPT-4

ML researchers joke that each month brings new surprises. I’d like to be less surprised in the coming month, so I’ve tried to predict what GPT-4 will bring (or PaLM-2, Meerkat, …).
Three years after GPT-3 only three companies have the secret sauce for large language models (LLMs) and write about them: OpenAI, DeepMind, and Google. I expect the next big model to be from one of the trio - most obviously OpenAI, which conspicuously missed its spring / summer GPT announcement this year.
Interesting predictions:
- Bigger context window (16k-32k)
- Tool use: can browse web, write code to find answer
- Massively scaling human feedback
- Incorporating user-generated data (if OpenAI)
- More data curation
- Improved scaling laws
Boring predictions (I only cover some of these):
- No scale up on param count (will be 200-400B params)
- Intermediate generation techniques
- Improved decoding techniques, hyperparameter search, tokenization
- Not multimodal (if OpenAI)
- Misc data comments (no synthetic data, mostly data available on web)
- Slightly better dataset filtering
Since I wrote the first draft of this post September 12th, Google published improved scaling laws on September 13th.



Interesting predictions
- Longer context. LLMs in production need to handle much longer inputs than the toy experiments in Playground, for reasoning over longer texts, using very long prompts, or including many in context examples. GPT-2 (2019) has a context window of 2^9 = 512 tokens. GPT-3 (2020) has a 4x larger window at 2^11 = 2048 tokens. Anthropic’s LLMs described in 2021 have a 4x larger window than GPT-3 at 2^13 = 8192 tokens, or about 6000 words. Noting the year-on-year fourfold increase, I expect the next big model in 2022 to have a context window of 2^15 = 32,768 tokens. This is a nontrivial engineering challenge, so I’ll hedge by saying it will be either 2^14 or 2^15.
- Psst! Here’s the context window for OpenAI’s
text-davinci-002(released March 15th).
- Psst! Here’s the context window for OpenAI’s

- Tool use. OpenAI, DeepMind, and Google have all released models in the past year trained to browse the internet, giving AI unfettered access to the world’s knowledge. Web browsing means that models don’t have to be retrained to teach them more information; they can simply Google facts they need. More generally, tool use helps models output correct answers and perform more specialized computations. Sufficiently large models already have latent tool use abilities: GPT-3 can be prompted to write Python code to answer math questions or even write API requests (!) to query for information it doesn’t know. I expect general model releases to start including tool use capabilities. Specifically, I predict GPT-4 will be trained to browse the web and write Python snippets to answer questions. However, this tool use capability will be heavily restricted to avoid e.g. inadvertently sending malicious API requests.
- Comment: After this post was first published, Adept released demos of their Act-1 model, “a large-scale Transformer trained to use digital tools”.
- Massively scaling human feedback. The Instruct-GPT variants feel much easier to interact with
than the 2020 models. The reinforcement learning with human feedback (RLHF) process steers the
model to respond with useful information, rather than spewing slurs and hate speech (like OPT, and GPT-3 back
in the day). This is the most tractable avenue for improving user interaction, so I expect OpenAI
to massively increase the amount of human feedback they collect and use for their model.
Instruct-GPT used 46k labeller-written and API prompts (see below; the exact breakdown is unclear). I think the amount of labeller-written prompts will 10x or 20x for GPT-4. The
hard part is ensuring sufficient diversity in the human generations, because people get tired and
it’s hard to come up with that many prompts. OpenAI hired 40 contractors to write prompts for
InstructGPT. I predict this will 10x. Incorporating user-generated data or being clever
about pseudo-tasks (text in existing datasets, which resembles prompts or instructions) could also
help.
- Comment: After this post was first published, DeepMind announced Sparrow, focusing on improving the kind of human feedback used for RLHF.
- Incorporating user-generated data. OpenAI’s InstructGPT paper used prompts generated by users in Playground (but not from the API in production, importantly). The main reason for mixing in user-generated data is that real-world prompts are far more complex than toy examples human labellers can come up with. Another upside is the sheer diversity, since you have more people writing prompts than you could have through managing your own labellers. However, Google, DeepMind, and FB do not offer commercial LLM APIs, so they have no way to obtain this data. AI21, OpenAI, and Cohere do. I couldn’t find how much Playground usage has increased, but given that the waitlist period for GPT-3 ended in November 2021, it seems reasonable to predict a 50x or 100x for amount of Playground data used. The increase would be much higher if they used production data, but I doubt they will because of the risk of including confidential information (of people who pay them, obviously).
- Pretraining data improvements. The most extreme scaling bulls would have you believe that dumping “whole mountains of barely filtered, mostly unedited scrapes of the internet into the eager maw of a hungry model” is the way of the future. I’m confident there will be increasing attention to the pretraining data over the next 18 months, primarily focusing on processing data carefully and curating data sources. The amount of data will remain the dominant factor for performance (over quality), but companies will pluck low hanging fruit here. Note that for multimodal models, reducing noise in data is critical and matters more than scale: no amount of captions help multimodality if the captions do not describe what’s in the image.
- Comment: After this post was first published, Google released their latest multimodal trained on a aggressively filtered dataset dataset which filtered out 90% of the intial scrape.
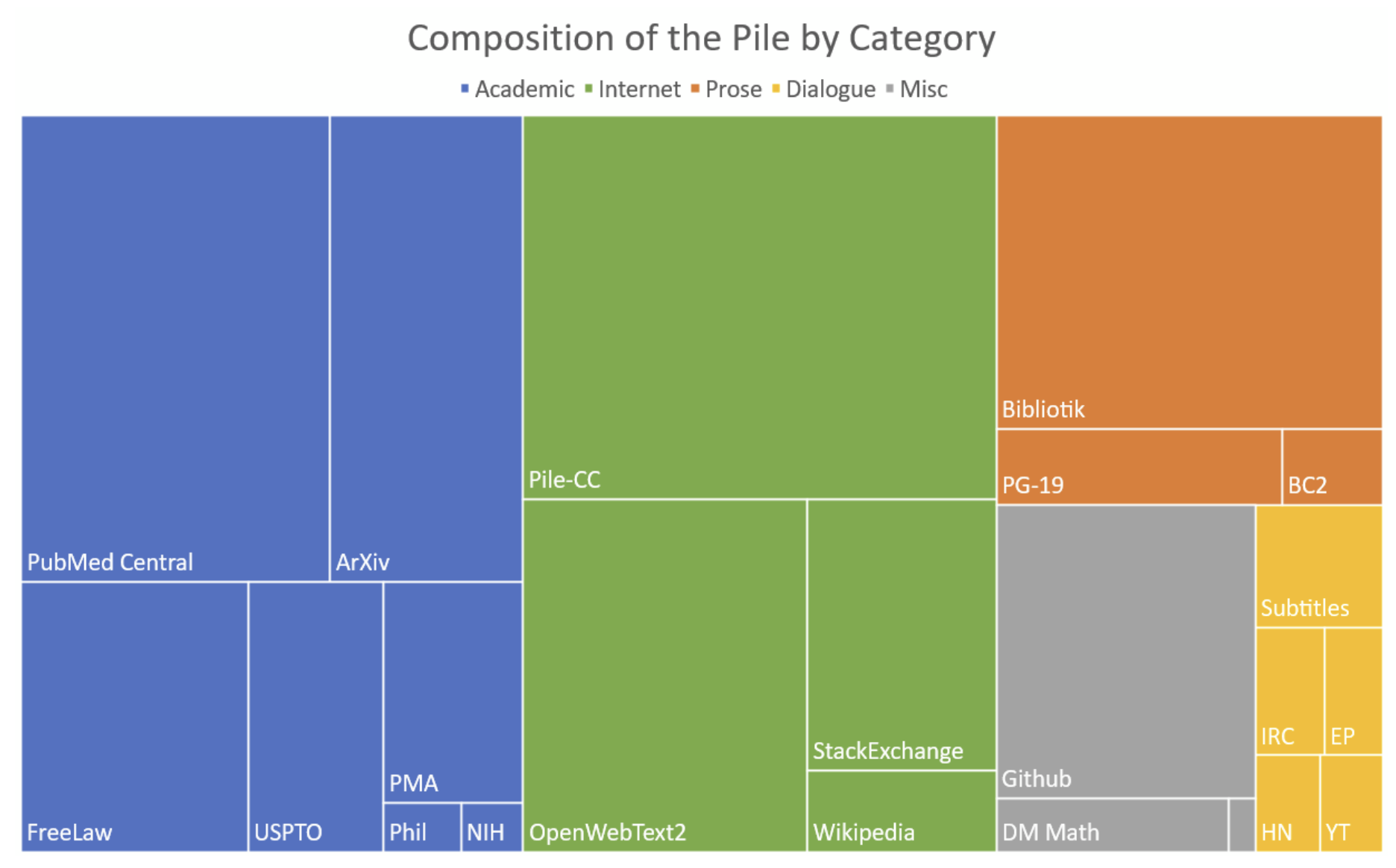
- More specialized data sources. While GPT-2 was trained primarily on WebText, a dataset scraped from outbound reddit links, GPT-3 included a (noisier) web scrape, Common Crawl, as well as two books corpora (Books1, Books2) and en-Wikipedia. The general trend has been to add more specialized data sources, for example the Pile (OPT, GLM-130B, etc) includes arXiv, PubMed, FreeLaw, StackExchange, USPTO, etc. I would expect the next big model to ingest even more PDFs and specialized documents from the internet (or focus on cleaning up those subsets of common crawl).
- It’s interesting to compare GPT-2 vs GPT-3 at similar parameter counts (1.5 vs 1.3B). On CoQA, GPT 2 1.5B: 55 F1; GPT-3 1.3B: 65 F1. On Lambada, GPT2 1.5B: 63%, GPT3 1.3B: 56% - there is a weird drop in the curve here, otherwise it would be around 72%. (Note that data is not the only difference between the two)
- Improved scaling laws. DeepMind’s Chinchilla work improved on earlier scaling laws. I believe there is still headroom for improved scaling behaviour. I predict the next big model released by Google or OpenAI will follow a different scaling law than Chinchilla.
- Comment: After this post was first published, Google released a scaling laws paper.
Boring predictions
- Not that large. I predict that the largest size for OpenAI and DeepMind’s next models to be between 200B to 400B parameters. Especially given DeepMind’s recent Chinchilla work, I would be extremely surprised if their next models were 1T parameters. My impression is that Google is most likely of the three to train a dense 1T model first.
- On preserving data structure. Structured data like tables seem to improve in-context learning. The intuition is that each row or example functions like few-shot prompt examples, so the structure is similar to in-context learning. My understanding is that web scrapes often mangle table structure, so it’s possible that the next big model will specially process this kind of structured data. I think this starts to get too into the weeds and is likely not worth doing as part of the pretraining data pipeline.
- On data source diversity. It’s hard to improve over web crawls for data source diversity per se, unless you start digitizing physical media (like scanning books), converting other digital sources (like video captions), or crawling social media, which causes serious privacy concerns, so I don’t expect a concerted effort on this front.
- On synthetic data. I do not expect any inclusion of synthetic data in the pretraining data, even for code or math datasets. The research in this area is still nascent - we don’t know what makes for good synthetic data - and there is enough data from natural sources, so synthetic data is not yet needed.
- Improved decoding techniques, hyperparameter search, tokenization. These are all relatively small improvements, so they may not be included. Improving tokenization (e.g. tokenizing all digits separately to improve math performance) seems like a clear win for mathematical comprehension.
- More dataset filtering. Works since GPT-3 (2020) usually filter the web scrape part of their dataset with e.g. a quality classifier trained on a higher quality dataset such as WebText, Wikipedia, and books. This is a blunt approach which filters out mangled or empty documents, but may resemble document similarity for OOD high quality documents; I speculate that a classifier with only WebText for positive examples would be looking for documents that redditors like and not just quality. There should be even better automated ways to automatically filter for high quality documents. However I think it’s unlikely the next big model will improve significantly in this regard, because ML engineers don’t like to think about data and because it’s expensive to measure how improving data quality improves model performance (need to train a model). Also, I think most easy improvements here will get washed away by scale.
Predicting performance
The world’s best (disclosed) LLM is locked away by Google. Neither has anyone announced a model combining well-known separate improvements. The uncertainty around how the best or best possible models today behave ripples into the future. The next best model jumps off from a model we don’t have access to. Do iterative techniques combine, brick by brick, to build higher? Or does each new trick substitute for another?
My predictions above are about technical changes, not qualitative differences in experience or quantitative performance differences. I expect the biggest qualitative difference will be that it’s much easier to interact with the model - that it seems to always guess what you want, even if you haven’t been very clear about your intent. Most people want similar things from the model, so scaling human feedback will get you very far. Prompt engineering is a hack! It means your model isn’t ready for users.
On benchmark performance numbers: I’ll save the hot takes for another day.
Staying up to date
I track the latest LLMs (and other big models) at foundationmodeltracker.com, along with info about released weights, code, data, and other useful data points. Follow @model_tracker for updates.
Endnotes
Thanks for reading the first post on my personal blog! I welcome discussion and constructive feedback, whether about the contents of this post or the writing. Safety note: I don’t think this type of forecasting worsens racing. Let me know if you disagree.
References above are not comprehensive. If you feel an important paper should be included, feel free to tweet it @thomasiliao.
Thanks to Rohan Taori, Charlie Snell, and asara for comments.
Changelog
- 2022-09-15: Added changelog
